Research Questions ¶
Identifying negative experiences and unmet needs ¶
Pipeline
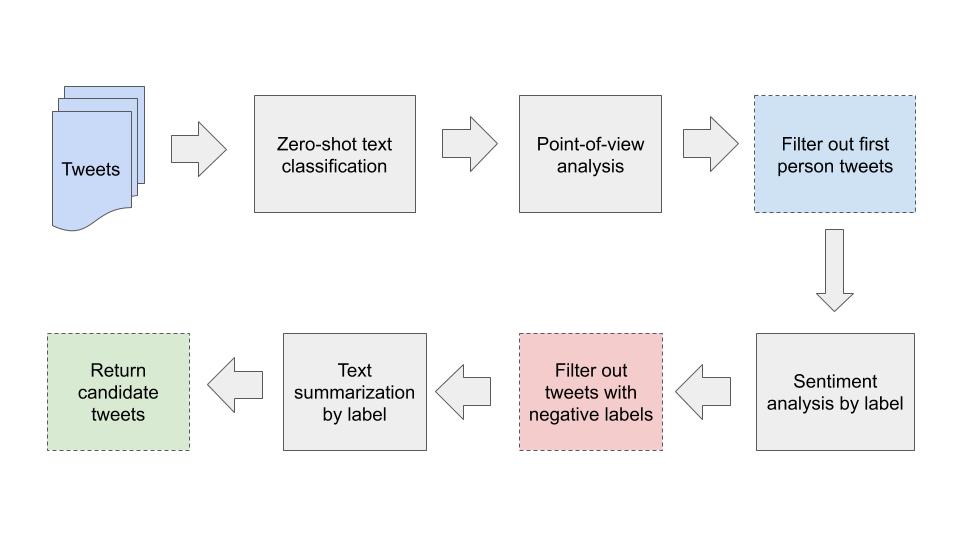
Approach
We begin by identifying the topics discussed in each tweet by assigning labels via zero-shot text classification. In order to highlight tweets from users who were personally affected by Cyclone Amphan, the data is then filtered to include only first person tweets using the point-of-view analysis. We narrow down our focus to the labels that have a median negative sentiment with the assumption that negative experiences are more likely to suggest unmet needs. We then report representative tweets using extractive summarization techniques to identify the dominant themes within each label.
Identifying narratives and influential users ¶
Pipeline

Approach
We address this question through the usage of user vectors as a means of positioning users in a two dimensional space. The network’s edges are assigned based on the number of retweets and/or replies among users. These users can now be grouped into different communities using two different methods: 1) discourse-based, where the clustering is done on the embedding features and 2) community-based, done through network clustering methods. For both clustering methods, the most popular users within each cluster are identified based on centrality measures and the number of followers the user has.